DataScientistFoundation-PCA
[TOC]
本文内容框架与撰写思路如下:
为什么需要进行降维?
现在大家做研究或讨论,往往都已经涉及“大数据”了——该专有名词具有多层含义,此处并不打算进行可以区分,只是说明“数据量变多了”。数据量变多,就难免会出现两个问题:噪声引入 和 数据重复 。
-
噪声引入:
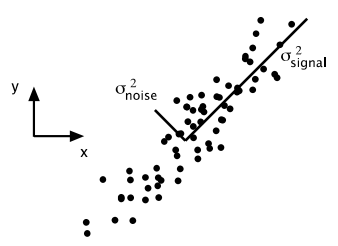
比如,我们通过摄像头记录下“弹簧振子”系统中弹簧末端的运动轨迹;不难发现,方差较小的方向上可以被认为是由于系统误差、测量误差等引入的波动。较小方差方向的量就可以被看做是“噪声”,这可以看做是一种比较合理的假设。
——对的,这是假设,所以就一定也存在其不合理之处,不合理之处就会导致算法失效。我认为这应该是一贯的思维意识,没有什么算法放之四海而皆准,想用,就得首先明白算法的假设及其局限性。
此时,确实想起来一个更有意思的例子,之前在与人讨论时,曾被用来质疑该降维思路的有效性。
比如,为了区分男生和女生,大家想出了许多判别特征,包括身高、体重、成绩、头发长短,是否戴眼镜(0和1表示)以及头发数目的多少(对的,你真的没有听错,虽然确实相当浪费计算资源,甚至想一想也没有多大意义,但是我们在机器学习过程中进行特征提取时,又何尝没有犯过这样的错误呢)。
但最后发现,一群人当中头发数目的方差好大,由上述思想断定“头发数目”是一个较好特征,必须予以保留。但,再想想,也只能呵呵了。
-
数据重复:

举个简单的例子,想量化一群人的特征,大家想出了很多办法和角度,比如身高、体重、性别等。但是呢,针对身高这一特征,有人用单位“米”表示,有人用“英寸”表示,然后都各执一词,将数据记录在表格里面。
但是,很显然啊,这两组数据就存在了重复——虽然使用了不同的单位,但是两者表示同一个特征。那如何判别呢,两组数据做一个相关性分析,很明显上面的例子会分析得到其相关系数为“1”。虽然记录了很多数据,但是并没有提供额外的信息量,这就是冗余redundancy。所以啊,没有提供额外信息量的数据,我们大可以放心地扔掉,也就是进行“降维”处理。
这又是一个假设,但显得更合理一些。此时,就有人在想:虽然两者可能不存在较大的相关性,那说不定存在“二次关系”或更复杂的非线性关系呢。是的,但研究起来就更难了。至少此时我们“扔掉”那些具有较大相关性的变量(之一)是非常合理的。
如何降维
O.K. 针对上面所提到的两个问题:噪声引入和数据重复,我们分别提供相应的解决策略:
- 保留具有较大方差的方向(变量或特征),那就计算各个变量的方差;
- 消除两两具有较大相关性的变量之一,那就计算两两之间的相关系数;
而这两个东西,恰恰都存在于一个统计量里面:协方差矩阵 。 好,那就看看该变量的计算公式:
其中 表示为得到的
数据集, 其任意一行表示某特征的所有数据,任意一列表示每次测试中所有的特征,即共有
个样本,每个样本含有
个特征。所以协方差矩阵就是
维度。
分为两部分来讨论:对角线元素与非对角线元素。
- 对角线元素 。 很明显表示某特征或变量的方差,也就是我们第一个问题所需要的变量。
- 非对角线元素 。 该协方差矩阵为 对称方阵 , 非对角线元素表示任意量元素之间的协方差,也就是相关性表征,又恰好是第二个问题所需要的变量。
基于上述两个问题,我们对该协方差矩阵提出一些目标或要求:
- 如果
是对角阵,非对角线元素为零,那再好不过了。我们就根据对角线元素大小排序,保留那些较大的对角线元素,删除较小的对角线元素 — 这样的操作对于数据集
而言就是去掉对应的行元素,最终达到降维的目的。
- 如果
投影到另外一个
空间中,保证在新空间中的协方差矩阵为
为对角阵。 有,
PCA 作为一种降维方法
关于其定义,我觉得Wikipedia写得已经很好了:
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components (or sometimes, principal modes of variation).
已经比较形象地解释了PCA的降维过程——解耦,想一想,这不就是协方差矩阵对角化的过程么?非常好地契合了我们对协方差矩阵 所提出的要求。
再通俗地解释一遍PCA降维过程就是:
通过对数据集的协方差矩阵解耦,依赖于方差排序,保留具有较大方差的变量,作为主要成分,达到维度降低的目的。
当然,降维方法不止有PCA,还有更多方法(以后会陆续补充),其中依赖于“方差”的筛选方法被称为PCA。 与之对比,LDA等提供了其他筛选方法,看起来也挺合理,作为另外的降维方法。
首先得摆出定理——“对称矩阵可对角化”,以此为依据,保证了我们之前对协方差矩阵 所提出的目标, 说明该目标也是可实现的。
后面,就介绍两种常见的“对角化”实现方法:
- 特征值-特征向量分解;
- 奇异值分解。
特征值-特征向量分解
这个应该是最容易想到的方法了,根据对特征值-特征向量的定义:
并全部写成矩阵的形式:
其中 为实对称阵,
由特征向量组成,其每一列表示一个特征向量;
为对角阵,其对角线元素为特征向量所对应的特征值
。
在Matlab代码中,其中关键一步是求该特征值-特征向量,参考函数eig。
奇异值分解
PCA 在 MNIST 数据库分析中应用
简单说明,以后凡介绍的机器学习基础知识,都会尽可能在MNIST进行实际处理说明,并且主要是跟踪 Kaggle的项目;
sklearn.decomposition.PCA
sklearn.decomposition.PCA 是由 scikit-learn 开源库所提供的一个class,能够用于PCA分析。
下面对该class的使用做一些简要的说明 ——其实就自己的学习过程来看,非常建议在初学时就接触第一手官方资料文档,而不是“二手加工”的资料;因为二手加工会非常容易因为别人的个人倾向影响自己,尤其是当存在中英文差异的时候,更应该先看官方资料(多数应该是英文),自己的理解,尤其是英文的某些词用法对建立自己的“第一印象”非常重要;而且,要始终强调自主思考,较大程度上的摆脱对别人的依赖。当然,这个过程常常是伴随着纠结、无助与痛苦的,但这也最利于成长。
课题组里有一个“大师级”的师兄,有一次在组会上大家向其请教,结果师兄只是微微一笑,说 自己只是多看开发文档而已。好的开发文档写得已经足够清晰,提供了几乎所有我们足够依赖的信息,所以又何必东奔西跑在搜索引擎上打开一堆不怎么细心消化的Tab呢。
所以,友情提示 :后面都是我个人的二次加工,谨慎阅读;我写出来主要是给自己看,练手之用。
在“二次加工”之前,我觉得有必要“逆向思考”——如果这个PCA算法库让我自己来开发的话,我会怎么做呢?对啊,自己来开发,毕竟我们也已经花费了大把的时间和精力把算法原理与公式都推导了一遍,关于“实现”该算法,我们至少也完成了20-30%的工作量了吧。并且把这套思路给梳理一遍,再把该算法的源代码看一遍,一定能功力长进不少。——庆幸的是,scikit-learn提供了Python实现的 PCA算法源代码,并且托管到Github上;对于大多数开源代码或项目都是这套思路,很赞。另外一方面,当写程序到一定水平时,常常在想“如何做下一步提高呢”:一方面可以通过实际项目加强代码能力,而另外一方面,通过阅读优秀的代码也是重要的提高途径。
下面就梳理下:如果让我来做,我会如何去完成:
- 输入接口:
- 拿到样本矩阵X,首先明确其行列的意义,或者此时可以统一接口; X - shape (n_samples, n_features)
- 降维空间的参数,所保留的“主元”维数;
- 是否进行去均值与归一化处理;
- 输出接口:
- 正交化投影矩阵P,并根据“主元”维数进行截取;
- 从大到小排序后的方差或百分比,以便用于调整保留的“主元”维数;
- 算法思路:(特征值-特征向量的求解方法)
- 根据输入参数要求进行去均值与归一化处理;
- 计算协方差矩阵;
- 求解特征值-特征向量;
- 根据特征值-特征向量进行排序,保留“主元”的特征向量,作为正交化投影矩阵;
- 其他,当然还有可能包含一些优化参数等,根据不同的语言进行对应处理; 或者根据实际需求,在此基础上进行添砖加瓦。
- 如何用?
那就是从上述 PCA 函数中已经得到了投影矩阵P,只需要对应与相应的样本矩阵(训练样本或测试样本)进行相乘(矩阵左乘或右乘),便可得到了对应降维后的矩阵。
- 小结:
然而,不得不承认,这还是一种“面向过程”的思路,我们能不能“面向对象”呢?——目标之一,就是实现数据与方法和结合。
O.K. 我能想到的差不多就是这样了,这个过程我之前用MATLAB代码实现过,参考Google研究人员的 一篇文章,最后也有代码参考,非常简单,不再引述。
再去看看 开源库是如何实现的
参考 sklearn.decomposition.PCA Documentation 从上至下,次序梳理如下:
- 首先,这是一个
class, O.K. 终于找到对象了; - 主要使用了
SVD-Singular Value Decomposition的求解方法,这个上面有提到; - 输入接口:
-
n_components指定保留的主元维数; -
copy是否保留原样本矩阵; -
whiten是否进行白化; -
svd_solver求解SVD过程中的优化处理; -
toltolerance for singular values -
iterated_powernumber of iterations for the power methods computed bysvd_solver, 没啥可说的——知道,但是搞不懂; -
random_statePseudo Random Number generator seed control 没啥可说的——知道,但是搞不懂; - 属性,一定程度上可以理解为 输出接口 吧:
-
components_,array-[n_components, n_features]维度;这就是 正交投影矩阵 ,也就是在自己推导过程中一直想要的矩阵P。但是注意其维数,表示已经选取了“主元”部分的 正交投影矩阵 ,其每一行表示一个主元方向。所以,当如果直接通过矩阵相乘的形式对原样本矩阵进行降维的话,直接使用np.dot(X, pca.components_.T),注意其中对该 正交投影矩阵 的转置。并且,注意PCA模型中的参数whiten=True/False及均值的问题,“其他说明”部分有例程讨论。 -
explained_variance_,array, [n_components]保留主元维度所对应的方差,按照从大到小进行排序; -
explained_variance_ratio_,array, [n_components]虽然能看到变量explained_variance_但是还是不够直观——其实我们使用PCA还有一种意识,就是认为所含信息的程度默认为与各个维度的方差成正比,比如我们一般会说,“OK, 那我保留95%的主要信息吧”。其实就是说,所保留主元的方差占总方差的95% 。这也就是为什么,在我们尝试使用PCA降维时,先观察下排序后的各个维度所含信息程度。如下图所示,比较直观。
-
mean_样本的均值。似乎没什么好说的,但是常常忽略,针对样本数据集进行降维运算时(比如通过上面所提到的矩阵乘法),在whiten=False情况下更准确的方法是np.dot(X-X.mean(axis=0), pca.components_.T) -
n_components_int主元的维数,由输入直接确定,没什么可说的; -
noise_variance_float有前面的理论可知,被“舍弃”部分作为“噪声”处理掉,也就是被舍弃部分的方差, “Pattern Recognition and Machine Learning” by C. Bishop, 12.2.1 p. 574 给出了计算公式(12.46)被舍弃部分的特征值均值作为噪声方差的估计,参阅下很容易理解; - 既然是“面向对象”, 有“属性”就会有“成员方法”methods:
-
fit(X[,y])fit the model with Xfit方法几乎在所有的机器学习模型中都会有该成员方法。一般来讲,机器学习模型都是基于训练数据集的,同时添加必要的其他模型设置参数,必要的情况下需要labels(有监督学习需要,而无监督学习不需要),就可以完成模型的训练,得到一个对象的实例化,不需要过问其中太多的细节部分;
针对该PCA模型,因为是无监督降维方法——而LDA可以被看做是有监督降维方法,所以不需要labels,模型训练的过程为:
```
from sklearn.decomposition import PCA
pca = PCA(n_components=n, whiten=True, copy=True) # model parameters
pca.fit(X) # training to obtain the MODEL
# pca as an object instanted from PCA-class
``` 2. `transform` `Apply dimensionality reduction to X` 既然得到了训练完成的`pca`模型,那就可以直接作用在任意数据集上——只要符合行列的含义,无论是训练样本还是测试样本,
``` newX = pca.transform(X) ```
这个过程就好像我们上面提到的矩阵相乘的方法——但是两者的计算结果略有差异,但并不是错误,尤其跟模型参数有关,#其他说明 部分会详细说明。 3. `fit_transform([X[,y]])` `fit the model with X and apply the dimensionality reduction on X` 很容易理解,这一步也就是是`fit` 与 `transform` 的二合一过程;那我们去扣一扣[源代码](https://github.com/scikit-learn/scikit-learn/blob/4c65d8e/sklearn/decomposition/pca.py#L106)看看是否如此呢?
1. `fit()` 进行去均值、SVD分解、`whiten`处理,模型参数的幅值:`n_components`,`explained_variance_`,`components_`,`explained_variance_ratio_` 等,但很关键,并没有对X进行降维处理,因为这仅仅是 __模型训练__ ;
2. `transform()`
```
X = X - self.mean_
X = fast_dot(X, self.components_.T)
return X
```
很明显是对样本矩阵X的降维运算——与自己之前提到的矩阵相乘方法不谋而合,因为我已经从原理上去理解啦,而不是把这些开源算法仅仅当做黑盒子在用。
3. `fit_transform` 从代码上来看,差不多是前两者的综合;
4. 但是从代码的注释中看到提醒:
```
copy: bool
If False, data passed to fit are overwritten
and running fit(X).transform(X) will not yield the expected results,
use fit_transform(X) instead
```
看来可以理解为`fit`+`transform`为`fit_transform`,但是在真正使用时,还是有一些小细节值得注意:当`copy=False`时,`fit(X)`已经把`X`给 _overwrite_ 并得到了降维后的`X`,再进行`transform`只能导致降维矩阵相乘两次,结果错误或矩阵维数不对无法相乘。 4. `get_covariance()` `compute data covariance with the generative model` _待详细补充_ 5. `get_params([deep])` `get parameters for this estimator` 模型参数,返回一个`dictionary` 6. `get_precision()` `compute data precision matrix with the generative model` _待详细补充_ 7. `inverse_transform(X[,y])` `transform data back to its original space` 能够将降维矩阵重新还原成原样本矩阵; 8. `score(X[,y])` `return the average log-likelihood of all samples` PCA 的 loss function就是用log-likelihood表示的,就算当前的结果,参考Bishop教材的相关章节 9. `score_samples(X)` `return the log-likelihood of each sameple` 即当每个样本输入到loss function里面时,计算的结果,很显然为n_samples的array。 10. `set_params()` `set the parameters of this estimator` 重新对模型参数进行配置; 11. `transform(X[,y])` `apply dimensionality reduction to X` 不再赘述。
### 其他说明
- 预处理;
- 归一化;
我将通过自己的一个近期的问题纠结作为实例进行总结说明,主要分为两个部分whiten=True与whiten=False,并且与自己通过Matlab计算结果进行对比,从差别中加深理解。
- 样本矩阵
X = np.array([[-1, -1, 1], [-2, -1, 2], [-3,-2, 3], [2,0,4], [1,2,3], [8,9,0]]) - 模型训练:
pca = PCA(n_components=3, whiten=False, copy=True) pca.fit(X) -
pca.components_得到降维矩阵——其中每一行表示主元方向array([[ 0.68823565, 0.71004984, -0.14886544], [ 0.42565749, -0.22904504, 0.87541651], [ 0.58749246, -0.66585854, -0.45987499]])
Matlab 计算结果如下,其每一列为主元方向,经对比,在方向的正负上略有差别,数值上相等。为什么会出现这个结果呢?因为在计算特征向量上,即使要求归一化,特征向量也并不唯一 v 与 -v 均可作为同一个\lambda 的特征向量,这个不用在意。
PC =
-0.6882 0.4257 0.5875
-0.7100 -0.2290 -0.6659
0.1489 0.8754 -0.4599
- 降维后的结果:
pca.transform(X) array([[ -2.62653032e+00, -1.30542708e+00, 9.02144811e-01], [ -3.46363141e+00, -8.55668057e-01, -1.45222646e-01], [ -5.01078234e+00, -1.76863995e-01, -5.26731563e-01], [ -2.98369866e-01, 2.36874989e+00, 6.19138684e-01], [ 5.82359607e-01, 6.09585810e-01, -8.40195867e-01], [ 1.08169543e+01, -6.40376570e-01, -9.13341835e-03]])Matlab 的结果:
X*PC ans = 1.5472 0.6788 -0.3815 2.3843 1.1286 -1.4289 3.9314 1.8074 -1.8104 -0.7810 4.3530 -0.6645 -1.6617 2.5938 -2.1238 -11.8963 1.3439 -1.2928咦,竟然不是相同的结果,这是为什么呢? 其实只要仔细,并且认真扣了源代码——前文中也有提到,这个差别在于是否有 去均值 的处理。所以,
(X' - repmat(mean(X'), size(X',1),1))*PC ans = 2.6265 -1.3054 0.9021 3.4636 -0.8557 -0.1452 5.0108 -0.1769 -0.5267 0.2984 2.3687 0.6191 -0.5824 0.6096 -0.8402 -10.8170 -0.6404 -0.0091所以,除了第一列的符号差别外,得到了相同的结果,这才算理清。
O.K. 下面讨论下 whiten=True的情况。我们先把吻合的计算结果梳理清楚,然后再回过头来理解。
- 模型训练:
pca = PCA(n_components=3, whiten=True, copy=True) pca.fit(X) - 降维矩阵, 与前者相同没有任何变化
pca.transform(X) array([[ -2.62653032e+00, -1.30542708e+00, 9.02144811e-01], [ -3.46363141e+00, -8.55668057e-01, -1.45222646e-01], [ -5.01078234e+00, -1.76863995e-01, -5.26731563e-01], [ -2.98369866e-01, 2.36874989e+00, 6.19138684e-01], [ 5.82359607e-01, 6.09585810e-01, -8.40195867e-01], [ 1.08169543e+01, -6.40376570e-01, -9.13341835e-03]]) - 降维后的结果,
pca.transform(X) array([[-0.50635505, -1.07425024, 1.4892522 ], [-0.66773539, -0.70413862, -0.23973218], [-0.96600253, -0.14554332, -0.86952353], [-0.05752117, 1.94927023, 1.02206833], [ 0.11227006, 0.50163484, -1.38698746], [ 2.08534407, -0.52697289, -0.01507736]])然后,神奇的事情发生了,结果完全不一样了,究竟
whiten=True干了什么事情——也许你已经是高手或踩过这个坑,当然知道whiten=True发生了什么事情;但我作为初学者完全不知道跳出坑的办法啊。所以,那就继续往下看,看我是如何跳出坑的;并且其中也发现了另外一个不起眼的坑,或许你还真不知道呢。
如何跳出坑的?
- O.K. 那我就先把前后两个结果进行对比下,也就是
whiten=True/whiten=False看看会有什么情况。初步猜测,两者的差别就在于whiten matrix,当然,在我没有完全理解之前,这个概念时我瞎猜的。两者相除的结果为:array([[ 0.19278477, 0.82291095, 1.65079062], [ 0.19278477, 0.82291095, 1.65079062], [ 0.19278477, 0.82291095, 1.65079062], [ 0.19278477, 0.82291095, 1.65079062], [ 0.19278477, 0.82291095, 1.65079062], [ 0.19278477, 0.82291095, 1.65079062]])Wow! 真的好神奇啊,这就相当于对变换后的样本矩阵各个列元素逐步乘上
0.19278477, 0.82291095, 1.65079062, 但这些数字有神什么鬼呢?继续探索, - 然后稍微看了 Whitening Transformation 的Wikipedia解释,猛然间产生一个疑问。
… into a set of new variables whose covariance is the identity matrix meaning that they are uncorrelated and all have variance 1.
(我最初以为的数据处理流程为:zero-meaning -> whitening -> PCA -> dimensionality reduction)为什么会是这样呢?一旦真的whitening了,也就是协方差矩阵将成为一个单位阵identity matrix, 那么PCA的算法将没有任何意义。所以,我承认自己的理解上一定有什么问题出错了,但是哪里呢?
- 思前想后,想了一天,没有想明白,究竟是哪里出错了,上面的数据处理流程根本说不通?
就这样,我反复问自己“上面的数据处理流程根本说不通”,最后终于稍微开窍了——就是whitening的位置放错了,应该放在PCA之后;
O.K. 恍然大悟,如果是放在后面的话,whitening 也就非常容易理解了——就是将PCA降维后每列的数据(表示某一特征)进行标准化,只需要除以标准方差就可以;
对的啊,难道上面两个相除的结果,每列都相同,该不会是主元上的标准差吧?在前面pca.explained_variance_的主元方差为[26.90633536, 1.47670694, 0.36695771]并将标准差的倒数计算出来,为[0.19278477, 0.82291095, 1.65079062]。咦?神奇的事情再次发生,该结果与上面的相除结果完全吻合。说明“数据处理流程”中whitening 的位置确实在PCA处理之后,也打消了上面的疑惑。问题释然。
- 而如果能仔细一些,用Matlab计算样本矩阵的协方差,进而计算主元对应的方差,又会发现一些神奇之处
S = [32.2876024, 1.772048, 0.4403492], 啊?竟然连主元的方差计算都不一样。又是哪里出现了问题?将前面pca计算的主元方差与Matlab计算的结果对应相除,竟然得到了[1.2, 1.2, 1.2],神奇了,这是什么鬼呢?
我就在想,是不是我的样本矩阵出现了问题,那我再添加一行,编程7个样本,结果上述结果从1.2 变成了 1.167,然后我一下就意识到了这个数字是什么——分别是6/5与7/6,完全跟样本矩阵的行有关,为什么呢?为什么呢?
终于又想到了,在计算协方差矩阵时,正确的公式为: , 而常常在使用的时候,会等效地使用公式
那去翻一翻 PCA算法源代码 L328 其中使用了
sqrt(n_samples) 而不是 n-1,所以问题的根源也挖到了。
而之所以能存在这一点小的差别也完全是因为我这里测试的样本数量较小,当真正应用在实际数据处理过程中时,数据量足够大,完全可以忽略n与n-1之间的差别——确实,我用同样的方法去测试了下MNIST数据集,发现两者相除的结果就是1,或直接计算降维后样本矩阵的协方差 np.cov(newX.T)为单位阵。当数据样本较小时,对角线元素为n/n-1,其中n为样本数量,接近单位阵。此时虽然也进行了whiten操作,但限于上述的差别,并没有最终将样本矩阵真正白化。
——但此时也值得认真想一想,主元的方差真的很重要吗?并不一定,只需要保证方差间的排序不变,主元方向一致,并不影响后面的计算结果。
小结
至此,已经写完了待解决的问题及背景,PCA算法的原理,算法及代码的实现,最后也通过自己写的Matlab计算结果与sklearn.decomposition.PCA结果进行对比,理解了其中的差别,加深了PCA的实际应用。
但PCA算法并不是就这样结束了,后续还有 Kernel PCA、 Incremental PCA 、Model Selection with Probabilistic PCA 以及最容易进行对比的 LDA 和 ICA 后续都会持续总结与更新。
此时,暂时告一段落吧。